
LLMs for Product Managers
Machine Learning is the compass guiding us through the vast landscapes of information.

Hey Product People,
Exciting update! 🚀 Just added 100 new resources this week to Bookmarks.ProductMindset.io – your go-to hub for all things Product Management

Ready to level up? Explore now: Visit Now
What are LLMs
LLMs, or large language models, are a type of artificial intelligence (AI) that are trained on massive amounts of text data. This data can include books, articles, code, and even social media posts. By analyzing this data, LLMs learn the patterns and relationships between words, phrases, and sentences. This allows them to generate human-quality text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
Language Models (LMs) are probabilistic models designed to identify and learn statistical patterns in natural language. Their main function is to calculate the probability of a word following a given input sentence.

What is the difference between large language models and generative AI?
Generative AI is an umbrella term that refers to artificial intelligence models that have the capability to generate content. Generative AI can generate text, code, images, video, and music. Examples of generative AI include Midjourney, DALL-E, and ChatGPT.
Large language models are a type of generative AI that are trained on text and produce textual content. ChatGPT is a popular example of generative text AI.
All large language models are generative AI
Types of Large Language Models

Large Language Models (LLMs) can be broadly classified into three types – pre-training models, fine-tuning models, and multimodal models.
Pre-training models like GPT-3/GPT-3.5, T5, and XLNet are trained on vast amounts of data, allowing them to learn a wide range of language patterns and structures. These models excel at generating coherent and grammatically correct text on a variety of topics. They are used as a starting point for further training and fine-tuning for specific tasks.
Fine-tuning models like BERT, RoBERTa, and ALBERT are pre-trained on a large dataset and then fine-tuned on a smaller dataset for a specific task. These models are highly effective for tasks like sentiment analysis, question-answering, and text classification. They are often used in industrial applications where there is a need for task-specific language models.
Multimodal models like CLIP and DALL-E combine text with other modalities like images or video to create more robust language models. These models can understand the relationships between images and text, allowing them to generate text descriptions of images or even generate images from textual descriptions.
Each type of LLM has its unique strengths and weaknesses, and the choice of which one to use depends on the specific use case.
Why are large language models important?
Modern LLMs can understand and utilize language in a way that has been historically unfathomable to expect from a personal computer. These machine-learning models can generate text, summarize content, translate, rewrite, classify, categorize, analyze, and more. All of these abilities provide humans with a powerful toolset to augment our creativity and improve productivity to solve difficult problems.
Some of the most common uses for LLMs in a business setting may include:
Automation and efficiency
LLMs can help supplement or entirely take on the role of language-related tasks such as customer support, data analysis, and content generation. This automation can reduce operational costs while freeing up human resources for more strategic tasks.Generating insight
LLMs can quickly scan large volumes of text data, enabling businesses to better understand market trends and customer feedback by scraping sources like social media, reviews, and research papers, which can in turn help inform business decisions.Creating a better customer experience
LLMs help businesses deliver highly personalized content to their customers, driving engagement and improving the user experience. This may look like implementing a chatbot to provide round-the-clock customer support, tailoring marketing messages to specific user personas, or facilitating language translation and cross-cultural communication.
Challenges and limitations for LLMs
While there are many potential advantages to using an LLM in a business setting, there are also potential limitations to consider:
Cost
LLMs require significant resources to develop, train, and deploy. This is why many LLMs are built from foundation models, which are pretrained with NLP abilities and provide a baseline understanding of language from which more complex LLMs can be built on top of.Privacy and security
LLMs require access to a lot of information, and sometimes that includes customer information or proprietary business data. This is something to be especially cautious about if the model is deployed or accessed by third-party providers.Accuracy and bias
If a deep learning model is trained on data that is statistically biased, or doesn’t provide an accurate representation of the population, the output can be flawed. Unfortunately, existing human bias is often transferred to artificial intelligence, thus creating risk for discriminatory algorithms and bias outputs. As organizations continue to leverage AI for improved productivity and performance, it’s critical that strategies are put in place to minimize bias. This begins with inclusive design processes and a more thoughtful consideration of representative diversity within the collected data.
So, what is a transformer model?
A transformer model is the most common architecture of a large language model. It consists of an encoder and a decoder. A transformer model processes data by tokenizing the input, then simultaneously conducting mathematical equations to discover relationships between tokens. This enables the computer to see the patterns a human would see were it given the same query.
Transformer models work with self-attention mechanisms, which enables the model to learn more quickly than traditional models like long short-term memory models. Self-attention is what enables the transformer model to consider different parts of the sequence, or the entire context of a sentence, to generate predictions.
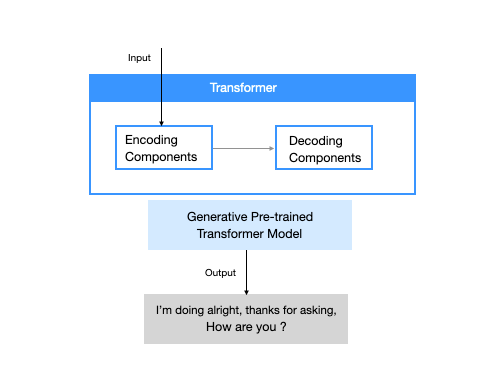
There are several classes of large language models that are suited for different types of use cases:
Encoder only: These models are typically suited for tasks that can understand language, such as classification and sentiment analysis. Examples of encoder-only models include BERT (Bidirectional Encoder Representations from Transformers).
Decoder only: This class of models is extremely good at generating language and content. Some use cases include story writing and blog generation. Examples of decoder-only architectures include GPT-3 (Generative Pretrained Transformer 3).
Encoder-decoder: These models combine the encoder and decoder components of the transformer architecture to both understand and generate content. Some use cases where this architecture shines include translation and summarization. Examples of encoder-decoder architectures include T5 (Text-to-Text Transformer).
Why Should Product Managers Embrace LLMs?
Product managers face a multitude of challenges, from ideation and market research to user feedback analysis and product optimization. LLMs can address these challenges by providing product managers with:
Augmented Creativity and Innovation: LLMs can generate novel ideas, concepts, and solutions by analyzing vast amounts of data and identifying patterns and connections that may be overlooked by humans.
Enhanced User Understanding: LLMs can analyze user feedback, social media conversations, and online reviews to gain deeper insights into user needs, preferences, and pain points.
Data-Driven Decision Making: LLMs can process and analyze large datasets, including product usage data, market trends, and competitor analysis, to inform data-driven decisions.
Improved Content Creation: LLMs can generate high-quality content, such as product descriptions, marketing materials, and user guides, saving product managers valuable time and resources.
Benefits of large language models (LLM)
The benefits offered by LLMs encompass various aspects:
Efficiency: LLMs automate tasks that involve the analysis of data, reducing the need for manual intervention and speeding up processes.
Scalability: These models can be scaled to handle large volumes of data, making them adaptable to a wide range of applications.
Performance: New-age LLMs are known for their exceptional performance, characterized by the capability to produce swift, low-latency responses.
Customization flexibility: LLMs offer a robust foundation that can be tailored to meet specific use cases. Through additional training and fine-tuning, enterprises can customize these models to precisely align with their unique requirements and objectives.
Multilingual support: LLMs can work with multiple languages, fostering global communication and information access.
Improved user experience: They enhance user interactions with chatbots, virtual assistants, and search engines, providing more meaningful and context-aware responses.
Limitations and challenges of large language models (LLM)
While LLMs offer remarkable capabilities, they come with their own set of limitations and challenges:
Bias amplification: LLMs can perpetuate biases present in the training data, leading to biased or discriminatory outputs.
Ethical concerns and hallucinations: They can generate harmful, misleading, or inappropriate content, raising ethical and content moderation concerns.
Interpretable outputs: Understanding why an LLM generates specific text can be challenging, making it difficult to ensure transparency and accountability.
Data privacy: Handling sensitive data with LLMs necessitates robust privacy measures to protect user information and maintain confidentiality.
Development and operational expenses: Implementing LLMs typically entails substantial investment in expensive graphics processing unit (GPU) hardware and extensive datasets to support the training process.
Glitch tokens: The use of maliciously designed prompts, referred to as glitch tokens, have the potential to disrupt the functionality of LLMs, highlighting the importance of robust security measures in LLM deployment.
Types of large language models (LLM)
Here’s a summary of four distinct types of large language models:
Zero shot: Zero-shot models are standard LLMs trained on generic data to provide reasonably accurate results for general use cases. These models do not necessitate additional training and are ready for immediate use.
Fine-tuned or domain-specific: Fine-tuned models go a step further by receiving additional training to enhance the effectiveness of the initial zero-shot model. An example is OpenAI Codex, which is frequently employed as an auto-completion programming tool for projects built on the foundation of GPT-3. These are also called specialized LLMs.
Language representation: Language representation models leverage deep learning techniques and transformers, the architectural basis of generative AI. These models are well-suited for natural language processing tasks, enabling the conversion of languages into various mediums, such as written text.
Multimodal: Multimodal LLMs possess the capability to handle both text and images, distinguishing them from their predecessors that were primarily designed for text generation. An example is GPT-4V, a more recent multimodal iteration of the model, capable of processing and generating content in multiple modalities.
Evaluation strategy for large language models
Having explored the inner workings of LLMs, their advantages, and drawbacks, the next step is to consider the evaluation process.
Understand your use case: Start by clearly defining your purpose and the specific tasks you want the LLM to perform. Understand the nature of the content generation, language understanding, or data processing required.
Inference speed and precision: Practicality is key when evaluating LLMs. Consider inference speed for large data sets; slow processing can hinder work. Choose models optimized for speed or handling big inputs, or prioritize precision for tasks like sentiment analysis, where accuracy is paramount and speed is secondary.
Context length and model size: This is a vital step.While some models have input length limits, others can handle longer inputs for comprehensive processing. Model size impacts infrastructure needs, with smaller models suitable for standard hardware. Yet, larger models offer enhanced capabilities but require more computational resources.
Review pre-trained models: Explore existing pre-trained LLMs like GPT-4, Claude, and others. Assess their capabilities, including language support, domain expertise, and multilingual capabilities, to see if they align with your needs.
Fine-tuning options: Evaluate whether fine-tuning the LLM is necessary to tailor it to your specific tasks. Some LLMs offer fine-tuning options, allowing you to customize the model for your unique requirements.
Testing and evaluation: Before making a final decision, conduct testing and experimentation with the LLM to evaluate its performance and suitability for your specific tasks. This may involve running pilot projects or conducting proof-of-concept trials. Such as assessing LLM outputs against labeled references allows for the calculation of accuracy metrics.
Ethical and security considerations: Assess ethical and security implications, especially if the LLM will handle sensitive data or generate content that may have legal or ethical implications.
Evaluate cost: Factor in the cost associated with using the LLM, including licensing fees, computational resources, model size, and any ongoing operational expenses. Utilize optimization methods such as quantization, hardware acceleration, or cloud services to enhance scalability and lower costs.
Licensing and commercial use: Selecting the right LLM involves careful consideration of licensing terms. While some open models come with restrictions on commercial use, others permit commercial applications. It’s crucial to review licensing terms to ensure they align with your business requirements.
Large language models use cases
Large language models can be used for several purposes:
Information retrieval: Think of Bing or Google. Whenever you use their search feature, you are relying on a large language model to produce information in response to a query. It's able to retrieve information, then summarize and communicate the answer in a conversational style.
Sentiment analysis: As applications of natural language processing, large language models enable companies to analyze the sentiment of textual data.
Text generation: Large language models are behind generative AI, like ChatGPT, and can generate text based on inputs. They can produce an example of text when prompted. For example: “Write me a poem about palm trees in the style of Emily Dickinson.”
Code generation: Like text generation, code generation is an application of generative AI. LLMs understand patterns, which enables them to generate code.
Chatbots and conversational AI: Large language models enable customer service chatbots or conversational AI to engage with customers, interpret the meaning of their queries or responses, and offer responses in turn.
Examples of popular large language models
Popular large language models have taken the world by storm. Many have been adopted by people across industries. You've no doubt heard of ChatGPT, a form of generative AI chatbot.
Other popular LLM models include:
PaLM: Google's Pathways Language Model (PaLM) is a transformer language model capable of common-sense and arithmetic reasoning, joke explanation, code generation, and translation.
BERT: The Bidirectional Encoder Representations from Transformers (BERT) language model was also developed at Google. It is a transformer-based model that can understand natural language and answer questions.
XLNet: A permutation language model, XLNet generated output predictions in a random order, which distinguishes it from BERT. It assesses the pattern of tokens encoded and then predicts tokens in random order, instead of a sequential order.
GPT: Generative pre-trained transformers are perhaps the best-known large language models. Developed by OpenAI, GPT is a popular foundational model whose numbered iterations are improvements on their predecessors (GPT-3, GPT-4, etc.). It can be fine-tuned to perform specific tasks downstream. Examples of this are EinsteinGPT, developed by Salesforce for CRM, and Bloomberg's BloombergGPT for finance.
💻 Introductions (Mildly Technical)
State of GPT Overview by Andrej Karpathy Broad exploration of Large Language Model construction.
Language Modelling at Scale Gopher, ethical considerations, and retrieval.
Introduction to Large Language Models Exploring the capabilities of Large Language Models.
Computers Understanding Language Better Impact of Large Language Models on language comprehension.
AI Revolution - Transformers and LLMs by Elad Gil Insights into the transformative power of AI and Large Language Models.
100 ChatGPT Use Cases to Try Practical applications and scenarios for ChatGPT.
ScaleAI Guide to Large Language Models Comprehensive guide on Large Language Models.
📰 Articles (Intermediate)
What is ChatGPT and How Does It Work? by Stephen Wolfram In-depth exploration, also available as a book.
Improving Instruction Tuning for LLMs Strategies for enhancing tuning processes in Large Language Models.
Simple Word Embedding Tutorial Basic guide to word embedding techniques.
The Illustrated Word2Vec Visual exploration of Word2Vec methodology.
Efficient Estimation of Word Representations in Vector Space Methods for efficient word representation in vector space.
💬 LLM Specific Courses
DeepLearning.AI Short Course on Prompt Engineering Strategies for effective prompt engineering in LLMs.
Full Stack Deep Learning Free LLM Bootcamp Comprehensive bootcamp covering various aspects of LLMs.
📚 Large Language Model (LLM) Books
What is ChatGPT and Why Does It Work? by Stephen Wolfram A book providing an in-depth understanding of ChatGPT.
Machine Learning with PyTorch: Sebastian Raschka (et al) Incorporating PyTorch in machine learning with a focus on LLMs.
🎧 Podcast Episodes about Large Language Models and AI
Jensen Huang CEO of NVIDIA on No Priors Engaging discussion on No Priors podcast with notable episodes on Noam Brown and Matei Zaharia.
Oriol Vinyals: Deep Learning and AGI Podcast episode delving into deep learning and artificial general intelligence.
Dr. ANDREW LAMPINEN (Deepmind) - Natural Language, Symbols, and Grounding Exploration of natural language, symbols, and grounding in AI.
Dataframed #96 GPT-3 and our AI-Powered Future (July 2022) Insights on GPT-3 and its implications for the future.
Towards Data Science 129. Amber Teng - Building Apps with a New Generation of Language Models (Oct 2022) Discussion on building applications with the latest language models.
Vector Databases for Machine Learning. Pinecone on Practical AI Practical insights into vector databases for machine learning.